What’s the Difference between Computer Vision, Image Processing and Machine Learning?
In this page, you will learn about Machine Vision, Computer Vision and Image Processing. If you want to boost your project with the newest advancements of these powerful technologies, request a call from our experts.
Computer vision, image processing, signal processing, machine learning – you’ve heard the terms but what’s the difference between them? Each of these fields is based on the input of an image or signal. They process the signal and then give us altered output in return. So what distinguishes these fields from each other? The boundaries between these domains may seem obvious since their names already imply their goals and methodologies. However, these fields draw heavily from the methodologies of one another, which can make the boundaries between them blurry. In this article we’ll draw the distinction between the fields according to the type of input used, and more importantly, the methodologies and outputs that characterize each one.
Let’s start by defining the input used in each field. Many, if not all, inputs can be thought of as a type of a signal. We favor the engineering definition of a signal, that is, a signal is a sequence of discrete measurable observations obtained using a capturing device, be it a camera, a radar, ultrasound, a microphone, et cetera… The dimensionality of the input signal gives us the first distinction between the fields. Mono-channel sound waves can be thought of as a one-dimensional signal of amplitude over time, whereas a pictures are a two-dimensional signal, made up of rows and columns of pixels. Recording consecutive images over time produces video which can be thought of as a three-dimensional signal.
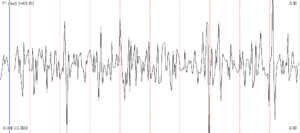
Let’s look at the x-ray as a prototypical example. Let’s assume we have acquired a single image from an x-ray machine. Image processing engineers (or software) would often have to improve the quality of the image before it passes to the physician’s display. Hence, the input is an image and the output is an image. Image processing is, as its name implies, all about the processing of images. Both the input and the output are images. Methods frequently used in image processing are: filtering, noise removal, edge detection, color processing and so forth. Software packages dedicated to image processing are, for example, Photoshop and Gimp.

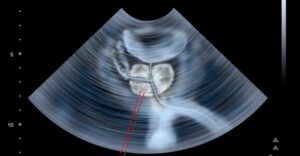
Extending beyond a single image, in computer vision we try to extract information from video. For example, we may want to count the number of cats passing by a certain point in the street as recorded by a video camera. Or, we may want to measure the distance run by a soccer player during the game and extract other statistics. Therefore, temporal information plays a major role in computer vision, much like it is with our own way of understanding the world.
But not all processes are understood to their fullest, which hinders our ability to construct a reliable and well-defined algorithm for our tasks. Machine learning methods then come to our rescue. Methodologies like Support Vector Machine (SVM) and Neural Networks are aimed at mimicking our way of reasoning without having full knowledge of how we do this. For example, a sonar machine placed to alert for intruders in oil drill facilities at sea needs to be able to detect a single diver in the vicinity of the facility. By sonar alone it is not possible to detect the difference between a big fish and a diver – more in-depth analysis is needed.

The following table summarizes the input and output of each domain:
| Domain | Input | Output |
| Image processing | Image | Image |
| Signal processing | Signal | Signal, quantitative information, e.g. Peak location, |
| Computer vision | Image/video | Image, quantitative/qualitative information, e.g. size, color, shape, classification, etc… |
| Machine learning | Any feature signal, from e.g. image, video, sound, etc.. | Signal, quantitative/qualitative information, image,… |
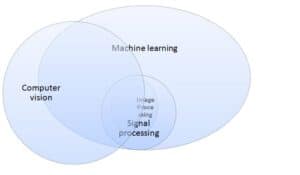
This can also be presented in a Venn diagram: